
• 데이터 가공하기 - (2) df[], (3)df.sort_values() (4)df.assign (5)df.agg(), df.groupby() (6)df.merge(), df.concat()
• 데이터 정제하기
🔹 (2) df[] : 조건에 맞는 열(변수) 추출하기
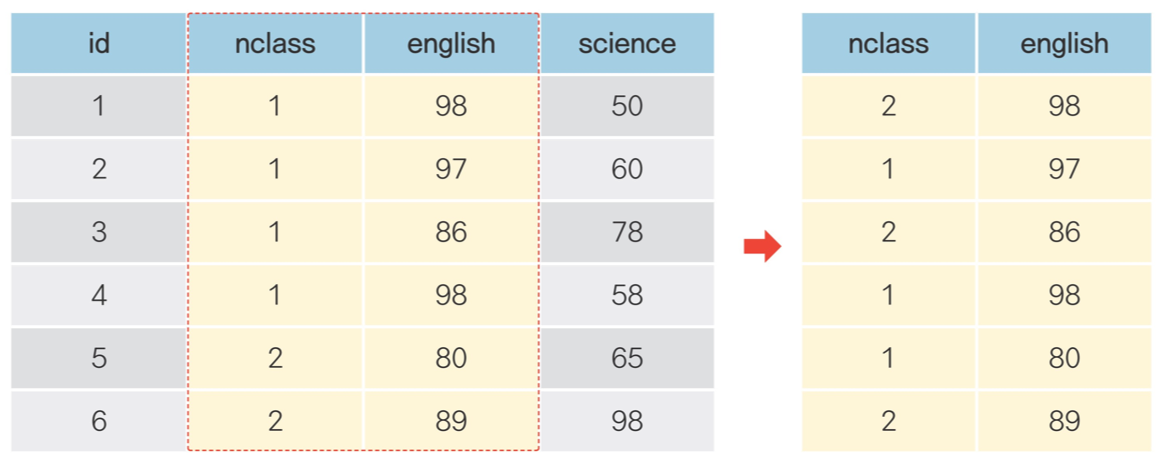
#데이터프레임명 뒤에 ['변수명']
#1-1 한 변수 (math점수) 추출해보기
>>> exam['math']
#1-2 여러 변수 추출해보기
>>> exam[['nclass', 'math', 'english']]
##변수가 1개일 때 데이터 프레임 유지하기 (그러니까 math라는 글자도 보이게 추출하기)
>>> exam[['math']]
#2-1 한 변수 제거해보기
>>> exam.drop(columns = 'math')
## 데이터프레임이 변경되는 것은 아님. 변경하고 싶을 땐 따로 할당해서 사용.
#2-2 여러 변수 제거해보기
>>> exam.drop(columns = ['math', 'english'])
#3 pandas 함수와 조합하기
#3-1 nclass가 1인 행만 추출한 다음 english값만 추출하기
>>> exam.query('nclass == 1')['english']
## \ 사용하기 : 가독성 있게 코드 줄 바꾸는 방법. \ 쓰기 전에는 꼭 띄고, 쓰고 난 후에는 공백(주석이나 띄어쓰기도 안됨)
❓ 분석해보기!
#Q1. mpg데이터는 11개 변수로 구성됩니다. 이 중 일부만 추출해 분석에 활용하려고 합니다.
#Q1-1. mpg데이터에서 category(자동차 종류), cty(도시 연비) 변수를 추출해 새로운 데이터를 만드세요.
>>> mpg_new = mpg[['category', 'cty']]
>>> mpg_new
#Q1-2. 새로 만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는지 확인하세요.
>>> mpg_new.head()
#Q2. 자동차 종류에 따라 도시 연비가 어떻게 다르지 알아보려고 합니다. 앞에서 추출한 데이터를 이용해 category(자동차 종류)가 'suv'인 자동차와 'compact'인 자동차 중 어떤 자동차의 cty(도시 연비) 평균이 더 높은지 알아보세요.
>>> mpg_new.query('category in ["suv"]')[['cty']].mean()
cty 13.5
>>> mpg_new.query('category in ["compact"]')[['cty']].mean()
cty 20.12766
🔹 (3) df.sort_values() : 순서대로 정렬하기
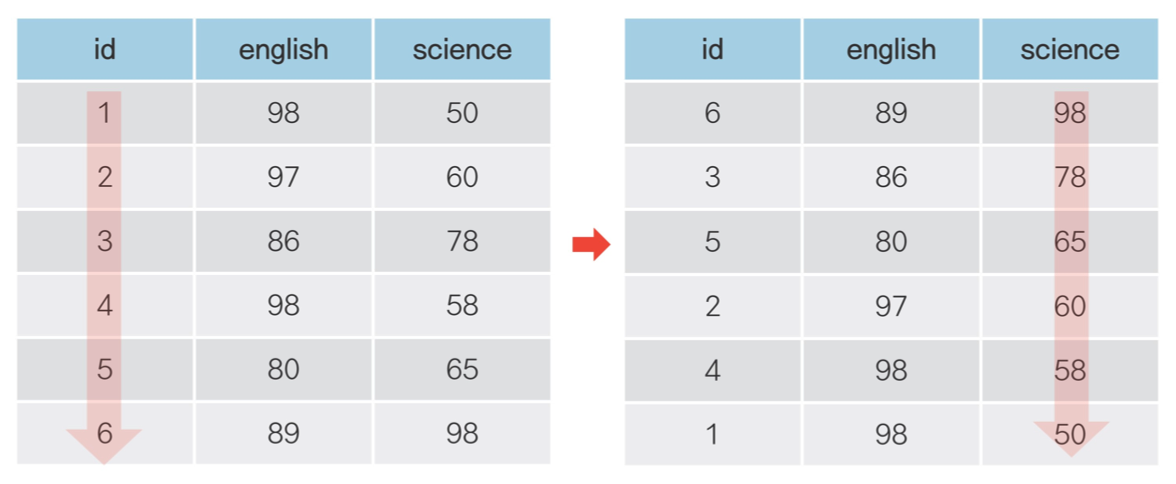
#1 오름차순으로 정렬하기
>>> exam.sort_values('math')
#2 내림차순으로 정렬하기
>>> exam.sort_values('math', ascending = False)
#3 여러 정렬 기준 적용하기
>>> exam.sort_values(['nclass', 'math'])
## nclass 기준으로 오름차순 정렬 후 수학 점수를 기준으로 오름차순 정렬
#4 변수별로 정렬 순서 다르게 지정하기
>>> exam.sort_values(['nclass', 'math'], ascending = [True, False])
❓ 분석해보기!
#Q1. 'audi'에서 생산한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은지 알아보려고 합니다. 'audi'에서 생산한 자동차 중 hwy가 1~5위에 해당하는 자동차의 데이터를 출력하세요.
>>> mpg.query('manufacturer == "audi"') \
>>> .sort_values(['hwy']) \
>>> .head()
🔹 (4) df.assign() : 파생변수 추가하기

# df.assign(새 변수명 = 변수를 만드는 공식)
#1 한 변수 (total) 추가해보기
>>> exam.assign(total = exam['math'] + exam['english'] + exam['science'])
#2 여러 변수 (total, mean) 추가해보기
>>> exam.assign(
>>> total = exam['math'] + exam['english'] + exam['science'],
>>> mean = (exam['math'] + exam['english'] + exam['science']) /3)
#3 df.assign()에 np.where() 적용하기
>>> exam.assign(test = np.where(exam['science'] >=60, 'pass', 'fail'))
## lambda를 사용해서 데이터 프레임명 줄여서 쓰기
# 긴 데이터 프레임명 지정
>>> long_name = pd.read_csv('exam.csv')
>>> long_name.assign(new = lambda x : x['math'] + x['english'] + x['science'])
## 위 2번의 경우 계속 앞에 exam을 붙였는데, 이처럼 반복되는 경우 lambda를 통해 약어로 지정하여 사용할 수 있다.
## 앞에서 만들어 놓은 파생변수를 이용해서 다시 파생 변수를 만들 때 lamda를 사용하지 않으면 에러!
❓ 분석해보기!
#Q1-1. mpg 데이터 복사본을 만들고,
>>> mpg_new = mpg.copy()
>>> mpg_new
#Q1-2. cty와 hwy를 더한 '합산 연비 변수'를 추가하세요.
>>> mpg_new = mpg_new.assign(total = mpg_new['cty'] + mpg_new['hwy'])
>>> mpg_new
#Q2 앞에서 만든 '합산 연비 변수'를 2로 나눠 '평균 연비 변수'를 추가하세요.
>>> mpg_new = mpg_new.assign(mean = mpg_new['total'] / 2)
>>> mpg_new
#Q3 '평균 연비 변수'가 가장 높은 자동차 3종의 데이터를 출력하세요.
>>> mpg_new.sort_values(['mean'], ascending = False).head(3)
#Q4 1~3번 문제를 해결할 수 있는 하나로 연결된 pandas 구문을 만들어 실행해 보세요. 데이터는 복사본 대신 mpg 원본을 이용하세요.
>>> mpg.assign(total = lambda x : x['cty'] + x['hwy'], \
mean = lambda x : x['total'] /2) \
.sort_values(['mean'], ascending =False) \
.head(3)
🔹 (5) df.agg() : 통계치 구하기, df.groupby() : 집단별로 나누기

#df.agg(요약값을 할당할 변수명 = ('요약할 변수', '함수'))
#전체 요약 통계량 구하기
>>> exam.agg(mean_math = ('math', 'mean'))
##agg()는 전체 요약한 값을 구하기 보단, groupby()에 적용해서 집단별로 요약값을 구할 때 사용. 함수에 '()' 안 씀.
##agg()에 자주 사용하는 요약 통계량 함수
##1. mean() : 평균
##2. std() : 표준편차
##3. sum() : 합계
##4. median() : 중앙값
##5. min() : 최솟값
##6. max() : 최댓값
##7. count() : 빈도(개수)# df.groupby('나눌 범주')
#1 집단별 요약 통계량 구하기
>>> exam.groupby('nclass').agg(mean_math = ('math', 'mean'))
## 근데 이렇게 하면 범주인 nclass가 인덱스로 바뀌어 mean_math보다 밑에 표시됨. 같이 표현하고 싶을땐?
>>> exam.groupby('nclass', as_index = False).agg(mean_math = ('math', 'mean'))
#2 여러 요약 통계량 한 번에 구하기
>>> exam.groupby('nclass') \
.agg(mean_math = ('math', 'mean'),
sum_math = ('math', 'sum'),
median_math = ('math', 'median'),
n = ('nclass', 'count'))
## agg() 대신 mena(), sum() 같은 요약 통계량 함수를 사용하면 모든 변수의 요약 통계량을 한번에 구할 수 있음.
>>> exam.groupby('nclass').mean()
#3 집단을 나눈 다음 다시 하위 집단으로 나누기
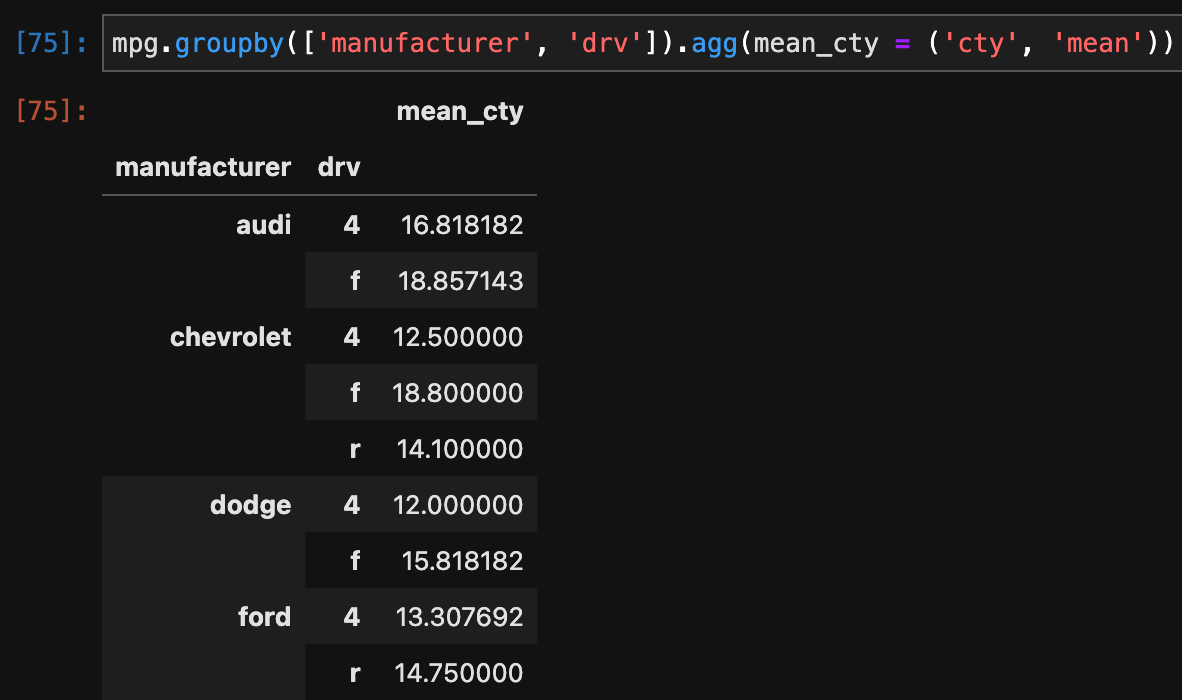
>>> mpg.groupby(['manufacturer', 'drv']).agg(mean_cty = ('cty', 'mean'))
## agg('변수명'=('변수', 'count')) 대신 value_counts()를 사용해서 빈도를 나타낼 수 있다.
>>> mpg.groupby('drv').agg(n= ('drv', 'count'))
>>> mpg['drv'].value_counts()
## value_counts()는 자동으로 빈도 기준으로 내림차순 정렬. 단, 출력 결과가 '시리즈'구조라서 query()는 적용 불가.
❓ 분석해보기!
#Q1. mpg데이터의 category는 자동차를 특징에 따라 'suv', 'compact' 등 일곱 종류로 분류한 변수입니다. 어떤 차종의 도시 연비가 높은지 비교해보려고 합니다. category별 cty평균을 구해보세요.
>>> mpg.groupby('category') \
.agg(cty_mean = ('cty', 'mean'))
#Q2. 앞 문제의 출력 결과는 category 값 알파벳순으로 정렬되어 있습니다. 어떤 차종의 도시 연비가 높은지 쉽게 알아볼 수 있도록 cty 평균이 높은 순으로 정렬해 출력하세요.
>>> mpg.groupby('category') \
.agg(cty_mean = ('cty', 'mean')) \
.sort_values(['cty_mean'], ascending = False)
#Q3. 어떤 회사 자동차의 hwy(고속도로 연비)가 가장 높은지 알아보려고 합니다. hwy평균이 가장 높은 회사 세 곳을 출력하세요.
>>> mpg.groupby('manufacturer') \
.agg(hwy_mean = ('hwy', 'mean')) \
.sort_values(['hwy_mean'], ascending = False) \
.head(3)
#Q4. 어떤 회사에서 'compact' 차종을 가장 많이 생산하는지 알아보려고 합니다. 회사별 'compact' 차종 수를 내림차순으로 정렬해 출력하세요.
>>> mpg.query('category == "compact"') \
.groupby('manufacturer') \
.agg(n = ('manufacturer', 'count')) \
.sort_values(['n'], ascending = False)
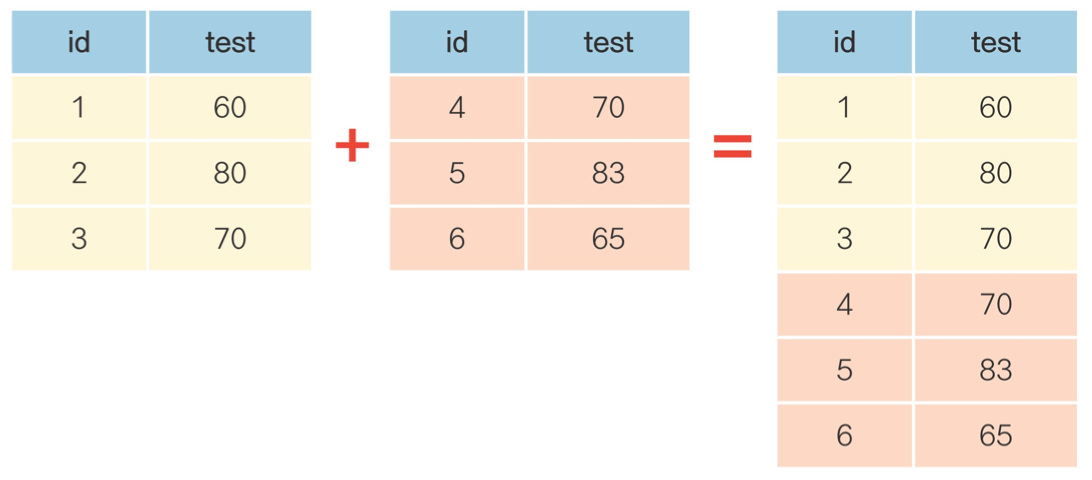
🔹 (6) df.merge() : 가로로(열) 데이터 합치기, df.concat() : 세로로(행) 데이터 합치기

# 새로 만들 데이터프레임명 = pd.merge(왼쪽 데이터, 오른쪽데이터, how ='left', on='결합할 기준')
## how = 'left' : 오른쪽에 입력한 데이터 프레임을 왼쪽 데이터 프레임에 결합한다 라는 뜻
# 중간고사 데이터 만들기
>>> test1 = pd.DataFrame({'id' : [1,2,3,4,5],
'midterm' : [60, 70, 80, 90, 100]})
# 기말고사 데이터 만들기
>>> test2 = pd.DataFrame({'id' : [1,2,3,4,5],
'final' : [70, 60, 83, 95, 99]})
# id를 기준으로 total이라는 데이터 프레임으로 합치기
>>> total = pd.merge(test1, test2, how= 'left', on = 'id')
>>> total#새로 만들 데이터프레임명 = pd.concat([결합할 데이터프레임명1, 결합할 데이터프레임명1])
# 학생 1~5번 시험 데이터 만들기
>>> group_a = pd.DataFrame({'id' : [1,2,3,4,5],
'test' : [60, 70, 80, 90, 100]})
# 학생 6~10번 시험 데이터 만들기
>>> group_b = pd.DataFrame({'id' : [6,7,8,9,10],
'test' : [70, 60, 83, 95, 99]})
# group_all이라는 새로운 데이터 프레임으로 합치기
>>> group_all = pd.concat([group_a, group_b])
🔹 참고) 치트 시트 : 패키지 사용법 요약 매뉴얼
❓ 분석해보기!
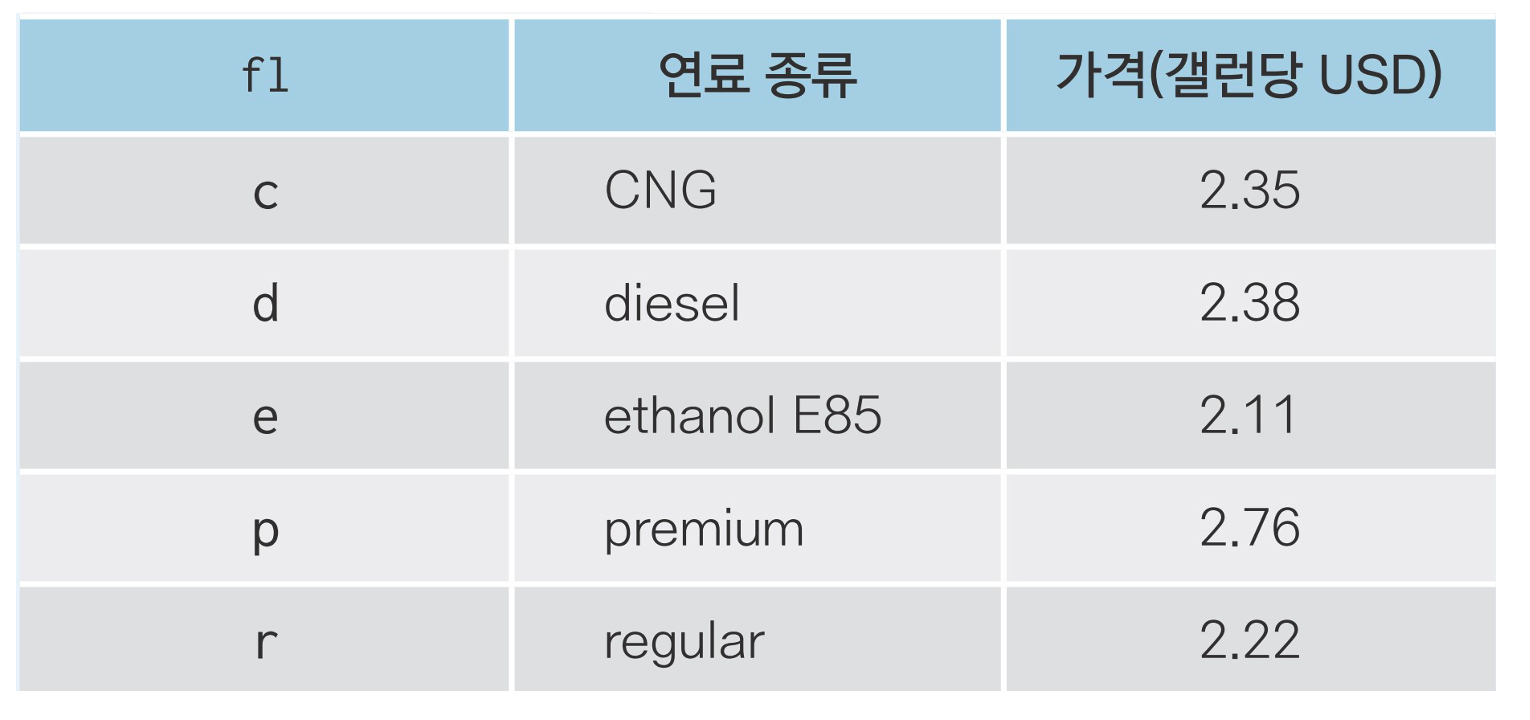
#Q1. mpg데이터의 fl변수는 자동차에 사용하는 연료(fuel)를 의미합니다. 다음은 자동차 연료별 가격을 나타낸 표입니다. 우선 이 정보를 이용해 연료와 가격으로 구성된 데이터 프레임을 만들어 보세요.
>>> fuel = pd.DataFrame({'fl' : ['c','d','e','p','r'],
'price_fl' : [2.35, 2.38, 2.11, 2.76, 2.22]})
>>> fuel
#Q2. mpg데이터에는 연료종류를 나타낸 fl변수는 있지만 연료 가격을 나타낸 변수는 없습니다. 앞에서 만든 fule데이터를 이용해 mpg데이터에 price_fl(연료 가격) 변수를 추가하세요.
>>> mpg = pd.merge(mpg, fuel, how = 'left', on = 'fl')
>>> mpg
#Q3. 연료 가격 변수가 잘 추가됐는지 확인하기 위해 model, fl, price_fl 변수를 추출해 앞부분 5행을 출력해보세요.
>>> mpg[['model', 'fl', 'price_fl']].head()
❓ 또 분석해보기!!
#미국 동북중부 437개 지역의 인구통계 정보를 담고 있는 midwest.csv를 사용해 데이터 분석 문제를 해결해보세요.
>>> midwest = pd.read_csv('midwest.csv')
>>> midwest
#Q1. popadults는 해당 지역의 성인 인구, poptotal은 전체 인구를 나타냅니다. midwest 데이터에 '전체 인구 대비 미성년 인구 백분율' 변수를 추가하세요.
>>> midwest = midwest.assign(child_ratio = (1 - midwest['popadults'] /
midwest['poptotal']) * 100)
>>> midwest
#Q2. 미성년 인구 백분율이 가장 높은 상위 5개 county(지역)의 미성년 인구 백분율을 출력하세요.
>>> midwest[['county','child_ratio']] \
.sort_values('child_ratio', ascending = False) \
.head()
#Q3. 분류표의 기준에 따라 미성년 비율 등급 변수를 추가하고, 각 등급에 몇 개의 지역이 있는지 알아보세요.
## 분류표 : large (40%이상), middle (30~40%이상), small (30%이상)
>>> midwest = midwest.assign(child_ratio_category = \
np.where(midwest['child_ratio'] >= 40, 'large', \
np.where(midwest['child_ratio'] >= 30, 'middle','small')
)
)
>>> midwest
>>> midwest.groupby('child_ratio_category') \
.agg(n = ('child_ratio_category', 'count'))
#Q4. popasian은 해당 지역의 아시아인 인구를 나타냅니다. '전체 인구 대비 아시아인 인구 백분율' 변수를 추가하고 하위 10개 지역의 state(주), county(지역), 아시아인 인구 백분율을 출력하세요.
>>> midwest = midwest.assign(popasian_ratio = midwest['popasian'] / midwest['poptotal'] * 100)
>>> midwest[['state', 'county', 'popasian_ratio']] \
.sort_values(['popasian_ratio']) \
.head(10)
🔷 데이터 정제하기

🔷 결측치 정제하기
🔹 결측치(missing value) ? : 누락된 값, 비어있는 값. 실제 데이터 분석 시 결측치를 확인하고 제거한 후에 분석을 시작해야 함.
#1 결측치를 찾기 전에, 우선 결측치가 있는 데이터프레임 만들기
>>> import pandas as pd
>>> import numpy as np
>>> df = pd.DataFrame({'sex' : ['M', 'F', np.nan, 'M', 'F'],
'score' : [5,4,3,4,np.nan]})
>>> df
## 결측치는 NumPy패키지의 np.nan으로 입력
## 표시는 NaN으로 나옴.
#2 결측치(NaN)이 있는 상태로 연산하면 출력 결과도 NaN으로 뜸.
>>> df['score'] + 1


🔹 결측치 제거하기
★#3 결측치 확인하기
>>> pd.isna(df)
#4 결측치 빈도 확인
>>> pd.isna(df).sum()
#5 결측치 있는 행 제거하기
>>> df.dropna(subset = ['score'])
#6 여러 변수에 결측치 없는 데이터 추출하고 df_nomiss로 저장해주기 (저장을 안하고 df그냥 조회해보면 원본 그대로 나옴)
>>> df_nomiss = df.dropna(subset = ['score', 'sex'])
>>> df_nomiss
#7 결측치가 하나라도 있으면 제거하기
>>> df_nomiss2 = df.dropna()
## 간편하긴하나 분석에 사용할 수 있는 변수까지 제거될 가능성이 있음.
## 예를들어, 성별, 소득, 지역의 데이터를 가지고 성별에 따른 소득 차이를 분석할 때, df.dropna()를 사용 시 지역에 NaN이 있는 행도 제거되어버림.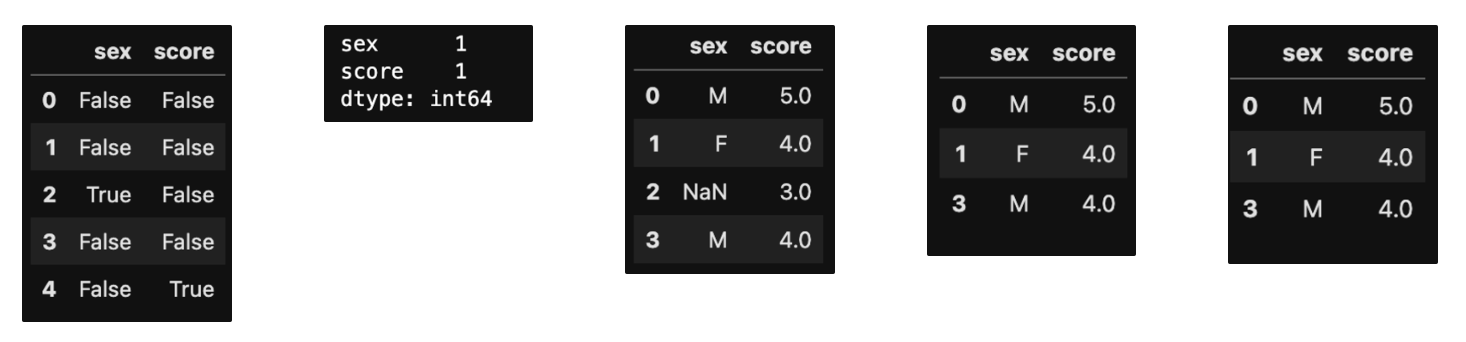
#8 결측치 제거하지 않고 분석하기
## pd.mean(), pd.sum(), groupby(), agg()는 결측치가 있으면 결측치를 자동으로 제거하고 연산함
>>> df['score'].mean()
4.0
>>> df['score'].sum()
16.0
>>> df.groupby('sex').agg(mean_score = ('score', 'mean'),
sum_score = ('score', 'sum'))
mean_score sum_score
sex
F 4.0 4.0
M 4.5 9.0
## 자동으로 결측치가 제거되는 기능은 편리하나, 결측치가 있는지 모른채 데이터를 다루게 되는 위험이 있음.
## 직접 결측치를 확인한 후 df.dropna()로 명시적으로 제거 권장
🔹 결측치 대체하기
🔹 결측치 대체하기 : 결측치가 적고 데이터가 크면 결측치를 제거하고 분석할 수 있는데, 데이터가 작고 결측치가 많으면 데이터 손실로 인해 분석 결과의 왜곡이 발생할 수 있음. 이럴 때 결측치를 대체해주면 됨.
🔹 결측치 대체법(imputation) : 결측치를 제거하는 대신 다른 값을 채워 넣는 방법. 평균값이나 최빈값 등 대표값을 구해 일괄 대체를 하거나, 통계 분석 기법으로 결측치의 예측값을 추정 후 대체
#1 위치를 직접 지정해서 원하는 값으로 바꾸기 (지금은 exam에 결측치값이 없으니 결측치를 임의로 넣어서 만들어줌)
>>> exam.loc[[2,7,14], ['math']] = np.nan
>>> exam
##데이터프레임명.loc[[행번호,행번호,행번호], ['칼럼명']] = 원하는 값
#2 위에서 만든 NaN값에 넣어줄 평균 값을 구해보기
>>> exam['math'].mean()
55.2
#3 평균값 55를 NaN에 넣어주기
>>> exam['math'] = exam['math'].fillna(55)
>>> exam
★#4 결측치가 잘 대체되었는지 확인하기
>>> exam['math'].isna().sum()
0

❓ 분석해보기!
# mpg데이터 원본에는 결측치가 없어서, 우선 mpg데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠습니다.
>>> mpg = pd.read_csv('mpg.csv')
>>> mpg.loc[[64, 123, 130, 152, 211], 'hwy'] = np.nan
#Q1. drv(구동 방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기 전에 우선 drv변수와 hwy변수에 결측치가 몇 개 있는지 알아보세요.
>>> mpg[['drv', 'hwy']].isna().sum()
#Q2. df.dropna()를 이용해 hwy변수의 결측치를 제거하고, 어떤 구동 방식의 hwy평균이 높은지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다.
>>> mpg.dropna(subset = ['hwy']) \
.groupby('drv') \
.agg(hwy_mean = ('hwy', 'mean'))
🔷 이상치 정제하기
🔷 이상치(anomaly)? : 정상 범위에서 크게 벗어난 값
🔹 이상치 제거하기 : 실제 데이터에 대부분 이상치가 들어가 있음. 제거하지 않으면 분석의 결과가 왜곡되므로 분석 전에 제거 작업 필요. 이상치는 결측치로 변환 후 제거
#1 이상치를 찾기 전에, 우선 이상치가 있는 데이터프레임 만들기
>>> df = pd.DataFrame({'sex' : [1,2,1,3,2,1],
'score' : [5,4,3,4,2,6]})
>>> df
## 'sex'가 3인 경우 이상치로 가정.
## 'score'가 5 이상인 경우 이상치로 가정.
#2 값이 적은 경우 빈도표를 만들어 이상치를 확인할 수 있음.
#2-1 'sex'의 빈도표 확인
>>> df['sex'].value_counts().sort_index()
#2-1 'score'의 빈도표 확인
>>> df['score'].value_counts().sort_index()
#3 이상치를 결측치로 바꾸어주기
#3-1 'sex'가 3인 경우, 이상치로 판단하여 NaN부여
>>> df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex'])
>>> df
#3-2 'score'가 5보다 크면 NaN 부여
>>> df['score'] = np.where(df['score']>5, np.nan, df['score'])
>>> df
#4 결측치로 바뀐 이상치였던 것들을 제거하기
>>> df.dropna(subset = ['sex', 'score'])
❗️ np.where()은 문자와 NaN을 함께 반환할 수 없음.
🔹 np.where()을 사용할 때 반환 값 중 문자가 있으면, np.nan으로 지정해도 문자로 'nan'을 반환해버림.
#1 예를 들어, 이런 데이터 프레임을 만들었음.
>>> df = pd.DataFrame({'x1' : [1,1,2,2]})
>>> df
#2 x2라는 컬럼을 만들면서, x1의 값이 1이면 a를, 1이 아니면 NaN을 반환하도록 명령.
>>> df['x2'] = np.where(df['x1'] == 1, 'a', np.nan)
>>> df
## 근데 지금 반환값에 'a'라는 문자가 들어가 있음.
#3 na의 결과를 확인해보니 na가 없다고 뜸.
>>> df.isna()

🔹 그럼 문자랑 NaN을 함께 구성하는 방법은?
#1 결측치로 만들 값에 임의로 문자를 부여함.
>>> df['x2'] = np.where(df['x1'] == 1, 'a', 'etc')
#2 df.replace()를 사용하여 임의로 부여한 문자를 np.nan으로 바꿔줌
>>> df['x2'] = df['x2'].replace('ect', np.nan)
#3 na 확인해보기
>>> df.isna()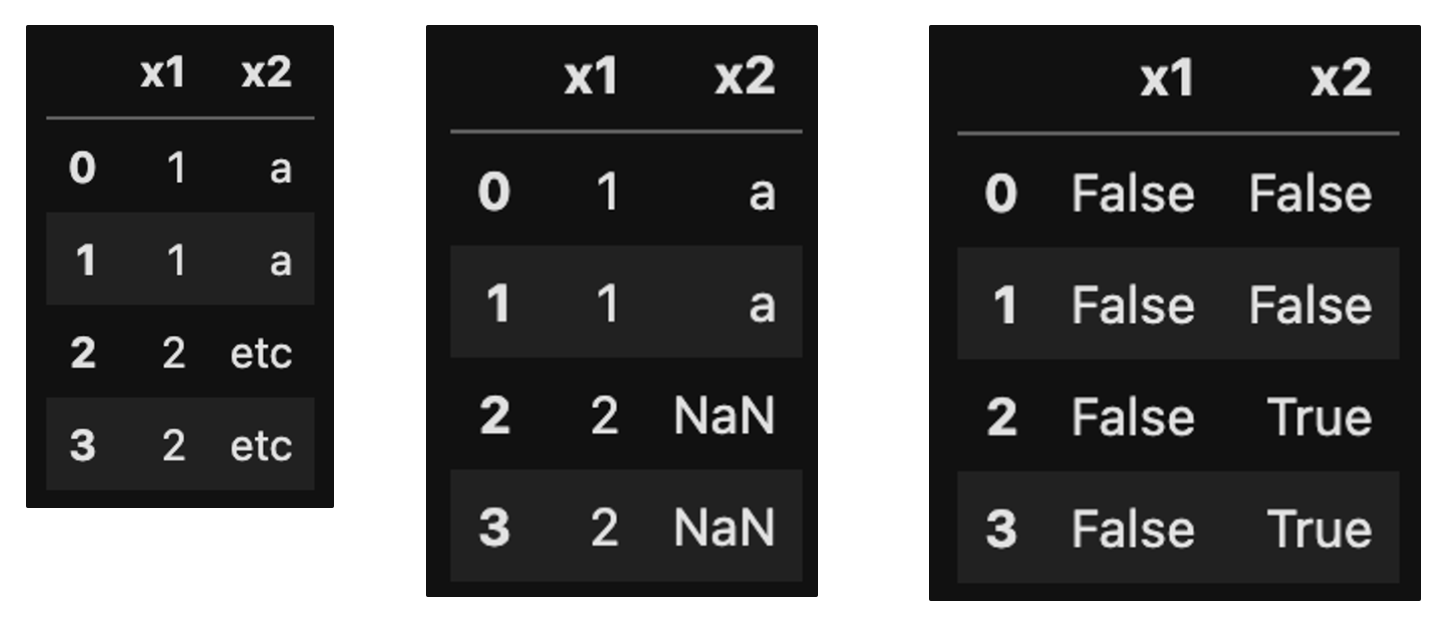
🔷 극단적인 이상치, 극단치(outlier) 파악하기
🔹 outlier 기준 정하기 : 논리적 판단, 통계적 기준, 상자 그림을 통해 파악
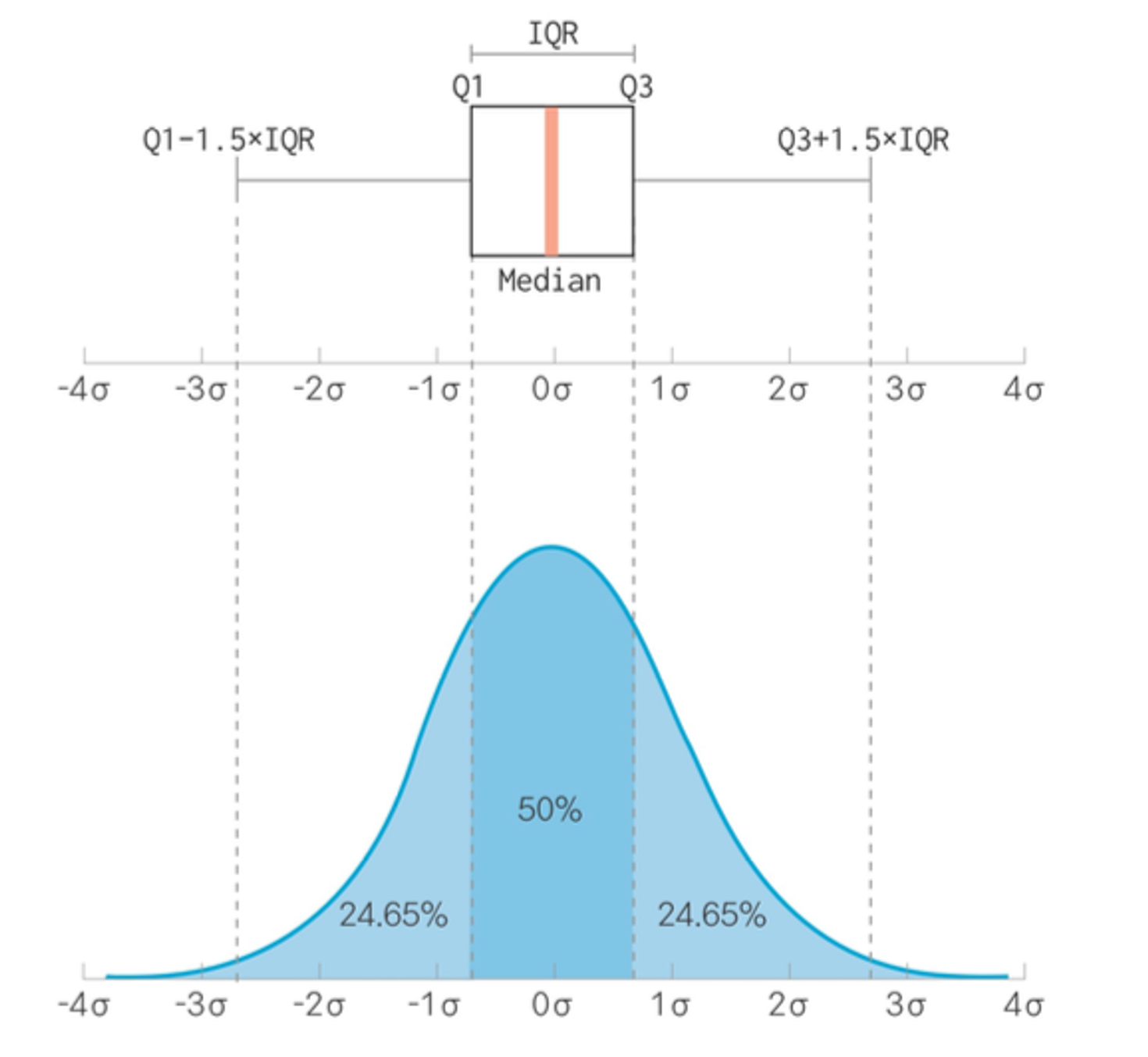
🔷 상자 그림 (box plot)? : 데이터의 분포를 상자 모양으로 표현한 그래프.
# 상자그림 그래프 불러오기
>>> import seaborn as sns
>>> sns.boxplot(data = mpg, y = 'hwy')
🔹 상자그림 그래프 해석

| 상자 그림 | 값 | 설명 |
| 상자 아래 세로선 | 아랫수염 | 하위 0~25% 내에 해당하는 값 |
| 상자 밑면 | 1사분위수(Q1) | 하위 25% 위치 값 |
| 상자 내 굵은 선 | 2사분위수(Q2) | 하위 50% 위치 값(중앙값) |
| 상자 윗면 | 3사분위수(Q3) | 하위 75% 위치 값 |
| 상자 위 세로선 | 윗수염 | 하위 75~100% 내에 해당하는 값 |
| 상자 밖 가로선 | 극단치 경계 | Q1, Q3 밖 1.5 IQR 내 최대값 |
| 상자 밖 점 표식 | 극단치 | Q1, Q3 밖 1.5 IQR을 벗어난 값 |
🔹 (1) 극단치 경계 : 이 부분을 넘어가면 극단치라고 생각해서 점으로 표현하겠습니다.
🔹 (2) IQR 이란? : 1사분위수에서 3사분위수까지의 거리. 박스의 높이라고 생각하면됨.

# 상자그림에서 표시된 부분의 값 자세히 구하기
#1 1사분위수 구하기
>>> pct25 = mpg['hwy'].quantile(.25)
>>> pct25
18.0
#2 3사분위수 구하기
>>> pct75 = mpg['hwy'].quantile(.75)
>>> pct75
27.0
#3 IQR 구하기
>>> IQR = pct75 - pct25
>>> IQR
9.0
#4 하한 구하기
>>> pct25 - 1.5 * IQR
4.5
#5 상한 구하기
>>> pct75 + 1.5 * IQR
40.5
# 극단치 제거하기
#1 극단치를 결측치로 처리하기
#1-1 하한(4.5)와 상한(40.5)를 벗어나면 NaN부여하기
>>> mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | mpg['hwy'] > 40.5, np.nan, mpg['hwy'])
#2 결측치 빈도 확인하기
>>> mpg['hwy'].isna().sum()
#3 결측치 제거하기
>>> mpg.dropna(subset = ['hwy'])
#4 결측치 제거하고 분석하기
>>> mpg.dropna(subset = ['hwy']) \
.groupby('drv') \
.agg(mean_hwy = ('hwy', 'mean'))
❓ 분석해보기!
# mpg데이터 원본에는 결측치가 없어서, 우선 mpg데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠습니다.
## drv(구동 방식) 변수의 값은 4, f, r 세 종류인데, 몇 개의 행에 존재할 수 없는 값 k 할당.
## cty(도시 연비) 변수도 몇 개의 행에 극단적으로 크거나 작은 값 할당.
>>> mpg = pd.read_csv('mpg.csv')
>>> mpg.loc[[9,13,57,92], 'drv'] = 'k'
>>> mpg.loc[[28,42,128,202], 'cty'] = [3,4,39,42]
#Q1-1. drv에 이상치가 있는지 확인하세요.
>>> mpg['drv'].value_counts().sort_index()
#Q1-2. 이상치를 결측처리하고 (결측 처리를 할 때는 df.isin()을 활용하세요.)
>>> mpg['drv'] = np.where(mpg['drv'].isin(['4', 'f', 'r']), mpg['drv'], np.nan)
#Q1-3. 다음 이상치가 사라졌는지 확인하세요.
>>> mpg['drv'].value_counts().sort_index()
#Q2-1. 상자 그림을 이용해 cty에 이상치가 있는지 확인하세요.
>>> sns.boxplot(data = mpg, y = 'cty')
#Q2-2. 상자 그림 기준으로 정상 범위를 벗어난 값을
>>> pct25 = mpg['cty'].quantile(.25)
>>> pct75 = mpg['cty'].quantile(.75)
>>> IQR = pct75 - pct25
#Q2-3. 정상 범위를 벗어난 값 : 하한 구하기
>>> pct25 - 1.5 * IQR
6.5
#Q2-4. 정상 범위를 벗어난 값 : 상한 구하기
>>> pct75 + 1.5 * IQR
26.5
#Q2-5. 결측 처리한 다음 (6.5 이하나, 265. 이상은 NaN부여)
>>> mpg['cty'] = np.where(((mpg['cty'] < 6.5) | (mpg['cty'] > 26.5)), np.nan, mpg['cty'])
#Q2-6. 다시 상자 그림을 만들어 이상치가 사라졌는지 확인하세요.
>>> sns.boxplot(data = mpg, y = 'cty')
#Q3. 두 변수의 이상치를 결측 처리했으니 이제 분석할 차례입니다. 이상치를 제거한 다음, drv별로 cty 평균이 어떻게 다른지 알아보세요. 하나의 pandas 구문으로 만드세요.
>>> mpg.dropna(subset = ['drv', 'cty']) \
.groupby('drv') \
.agg(mean_cty = ('cty', 'mean'))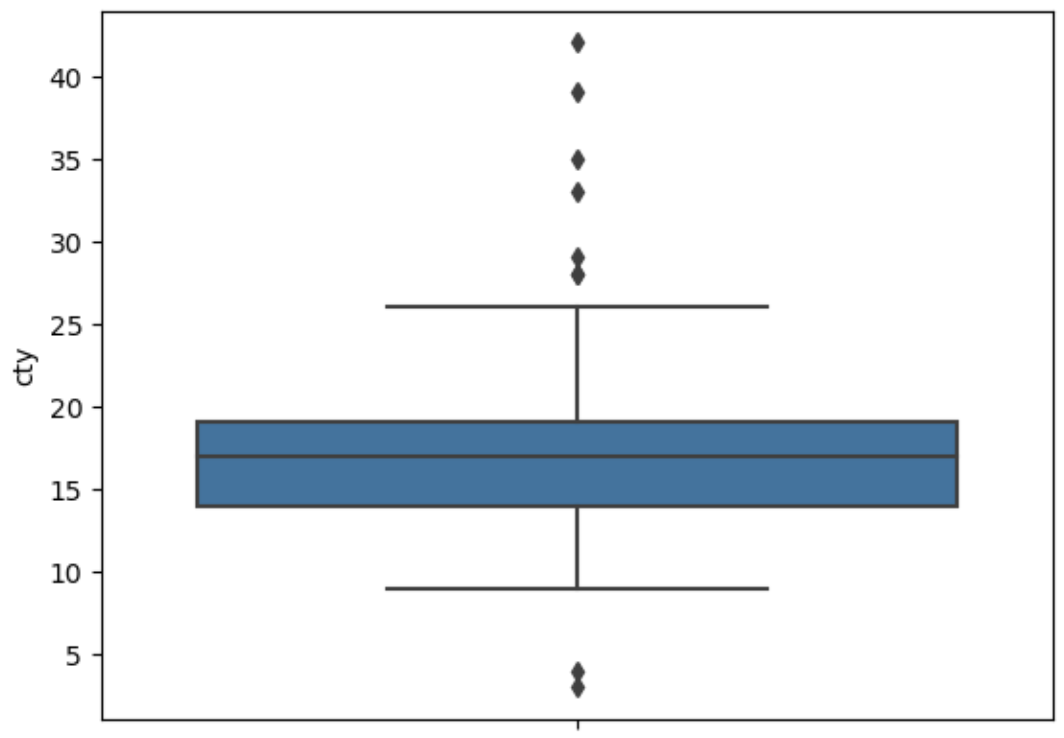

'[DA] 데이터 분석' 카테고리의 다른 글
| [성동1기 전Z전능 데이터 분석가] DAY36 - PYTHON PROJECT 1일차 (0) | 2023.12.04 |
|---|---|
| [성동1기 전Z전능 데이터 분석가] DAY35 - 파이썬 기초 (1) | 2023.12.01 |
| [성동1기 전Z전능 데이터 분석가] DAY33 (1) | 2023.11.29 |
| [성동1기 전Z전능 데이터 분석가] DAY32 - 파이썬 기초 (1) | 2023.11.28 |
| [성동1기 전Z전능 데이터 분석가] DAY31 - 파이썬 기초 (1) | 2023.11.27 |
• 데이터 가공하기 - (2) df[], (3)df.sort_values() (4)df.assign (5)df.agg(), df.groupby() (6)df.merge(), df.concat()
• 데이터 정제하기
🔹 (2) df[] : 조건에 맞는 열(변수) 추출하기
#데이터프레임명 뒤에 ['변수명'] #1-1 한 변수 (math점수) 추출해보기 >>> exam['math'] #1-2 여러 변수 추출해보기 >>> exam[['nclass', 'math', 'english']] ##변수가 1개일 때 데이터 프레임 유지하기 (그러니까 math라는 글자도 보이게 추출하기) >>> exam[['math']] #2-1 한 변수 제거해보기 >>> exam.drop(columns = 'math') ## 데이터프레임이 변경되는 것은 아님. 변경하고 싶을 땐 따로 할당해서 사용. #2-2 여러 변수 제거해보기 >>> exam.drop(columns = ['math', 'english']) #3 pandas 함수와 조합하기 #3-1 nclass가 1인 행만 추출한 다음 english값만 추출하기 >>> exam.query('nclass == 1')['english'] ## \ 사용하기 : 가독성 있게 코드 줄 바꾸는 방법. \ 쓰기 전에는 꼭 띄고, 쓰고 난 후에는 공백(주석이나 띄어쓰기도 안됨)
❓ 분석해보기!
#Q1. mpg데이터는 11개 변수로 구성됩니다. 이 중 일부만 추출해 분석에 활용하려고 합니다. #Q1-1. mpg데이터에서 category(자동차 종류), cty(도시 연비) 변수를 추출해 새로운 데이터를 만드세요. >>> mpg_new = mpg[['category', 'cty']] >>> mpg_new #Q1-2. 새로 만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는지 확인하세요. >>> mpg_new.head() #Q2. 자동차 종류에 따라 도시 연비가 어떻게 다르지 알아보려고 합니다. 앞에서 추출한 데이터를 이용해 category(자동차 종류)가 'suv'인 자동차와 'compact'인 자동차 중 어떤 자동차의 cty(도시 연비) 평균이 더 높은지 알아보세요. >>> mpg_new.query('category in ["suv"]')[['cty']].mean() cty 13.5 >>> mpg_new.query('category in ["compact"]')[['cty']].mean() cty 20.12766
🔹 (3) df.sort_values() : 순서대로 정렬하기
#1 오름차순으로 정렬하기 >>> exam.sort_values('math') #2 내림차순으로 정렬하기 >>> exam.sort_values('math', ascending = False) #3 여러 정렬 기준 적용하기 >>> exam.sort_values(['nclass', 'math']) ## nclass 기준으로 오름차순 정렬 후 수학 점수를 기준으로 오름차순 정렬 #4 변수별로 정렬 순서 다르게 지정하기 >>> exam.sort_values(['nclass', 'math'], ascending = [True, False])
❓ 분석해보기!
#Q1. 'audi'에서 생산한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은지 알아보려고 합니다. 'audi'에서 생산한 자동차 중 hwy가 1~5위에 해당하는 자동차의 데이터를 출력하세요. >>> mpg.query('manufacturer == "audi"') \ >>> .sort_values(['hwy']) \ >>> .head()
🔹 (4) df.assign() : 파생변수 추가하기
# df.assign(새 변수명 = 변수를 만드는 공식) #1 한 변수 (total) 추가해보기 >>> exam.assign(total = exam['math'] + exam['english'] + exam['science']) #2 여러 변수 (total, mean) 추가해보기 >>> exam.assign( >>> total = exam['math'] + exam['english'] + exam['science'], >>> mean = (exam['math'] + exam['english'] + exam['science']) /3) #3 df.assign()에 np.where() 적용하기 >>> exam.assign(test = np.where(exam['science'] >=60, 'pass', 'fail')) ## lambda를 사용해서 데이터 프레임명 줄여서 쓰기 # 긴 데이터 프레임명 지정 >>> long_name = pd.read_csv('exam.csv') >>> long_name.assign(new = lambda x : x['math'] + x['english'] + x['science']) ## 위 2번의 경우 계속 앞에 exam을 붙였는데, 이처럼 반복되는 경우 lambda를 통해 약어로 지정하여 사용할 수 있다. ## 앞에서 만들어 놓은 파생변수를 이용해서 다시 파생 변수를 만들 때 lamda를 사용하지 않으면 에러!
❓ 분석해보기!
#Q1-1. mpg 데이터 복사본을 만들고, >>> mpg_new = mpg.copy() >>> mpg_new #Q1-2. cty와 hwy를 더한 '합산 연비 변수'를 추가하세요. >>> mpg_new = mpg_new.assign(total = mpg_new['cty'] + mpg_new['hwy']) >>> mpg_new #Q2 앞에서 만든 '합산 연비 변수'를 2로 나눠 '평균 연비 변수'를 추가하세요. >>> mpg_new = mpg_new.assign(mean = mpg_new['total'] / 2) >>> mpg_new #Q3 '평균 연비 변수'가 가장 높은 자동차 3종의 데이터를 출력하세요. >>> mpg_new.sort_values(['mean'], ascending = False).head(3) #Q4 1~3번 문제를 해결할 수 있는 하나로 연결된 pandas 구문을 만들어 실행해 보세요. 데이터는 복사본 대신 mpg 원본을 이용하세요. >>> mpg.assign(total = lambda x : x['cty'] + x['hwy'], \ mean = lambda x : x['total'] /2) \ .sort_values(['mean'], ascending =False) \ .head(3)
🔹 (5) df.agg() : 통계치 구하기, df.groupby() : 집단별로 나누기
#df.agg(요약값을 할당할 변수명 = ('요약할 변수', '함수')) #전체 요약 통계량 구하기 >>> exam.agg(mean_math = ('math', 'mean')) ##agg()는 전체 요약한 값을 구하기 보단, groupby()에 적용해서 집단별로 요약값을 구할 때 사용. 함수에 '()' 안 씀. ##agg()에 자주 사용하는 요약 통계량 함수 ##1. mean() : 평균 ##2. std() : 표준편차 ##3. sum() : 합계 ##4. median() : 중앙값 ##5. min() : 최솟값 ##6. max() : 최댓값 ##7. count() : 빈도(개수)
# df.groupby('나눌 범주') #1 집단별 요약 통계량 구하기 >>> exam.groupby('nclass').agg(mean_math = ('math', 'mean')) ## 근데 이렇게 하면 범주인 nclass가 인덱스로 바뀌어 mean_math보다 밑에 표시됨. 같이 표현하고 싶을땐? >>> exam.groupby('nclass', as_index = False).agg(mean_math = ('math', 'mean')) #2 여러 요약 통계량 한 번에 구하기 >>> exam.groupby('nclass') \ .agg(mean_math = ('math', 'mean'), sum_math = ('math', 'sum'), median_math = ('math', 'median'), n = ('nclass', 'count')) ## agg() 대신 mena(), sum() 같은 요약 통계량 함수를 사용하면 모든 변수의 요약 통계량을 한번에 구할 수 있음. >>> exam.groupby('nclass').mean() #3 집단을 나눈 다음 다시 하위 집단으로 나누기 >>> mpg.groupby(['manufacturer', 'drv']).agg(mean_cty = ('cty', 'mean')) ## agg('변수명'=('변수', 'count')) 대신 value_counts()를 사용해서 빈도를 나타낼 수 있다. >>> mpg.groupby('drv').agg(n= ('drv', 'count')) >>> mpg['drv'].value_counts() ## value_counts()는 자동으로 빈도 기준으로 내림차순 정렬. 단, 출력 결과가 '시리즈'구조라서 query()는 적용 불가.
❓ 분석해보기!
#Q1. mpg데이터의 category는 자동차를 특징에 따라 'suv', 'compact' 등 일곱 종류로 분류한 변수입니다. 어떤 차종의 도시 연비가 높은지 비교해보려고 합니다. category별 cty평균을 구해보세요. >>> mpg.groupby('category') \ .agg(cty_mean = ('cty', 'mean')) #Q2. 앞 문제의 출력 결과는 category 값 알파벳순으로 정렬되어 있습니다. 어떤 차종의 도시 연비가 높은지 쉽게 알아볼 수 있도록 cty 평균이 높은 순으로 정렬해 출력하세요. >>> mpg.groupby('category') \ .agg(cty_mean = ('cty', 'mean')) \ .sort_values(['cty_mean'], ascending = False) #Q3. 어떤 회사 자동차의 hwy(고속도로 연비)가 가장 높은지 알아보려고 합니다. hwy평균이 가장 높은 회사 세 곳을 출력하세요. >>> mpg.groupby('manufacturer') \ .agg(hwy_mean = ('hwy', 'mean')) \ .sort_values(['hwy_mean'], ascending = False) \ .head(3) #Q4. 어떤 회사에서 'compact' 차종을 가장 많이 생산하는지 알아보려고 합니다. 회사별 'compact' 차종 수를 내림차순으로 정렬해 출력하세요. >>> mpg.query('category == "compact"') \ .groupby('manufacturer') \ .agg(n = ('manufacturer', 'count')) \ .sort_values(['n'], ascending = False)
🔹 (6) df.merge() : 가로로(열) 데이터 합치기, df.concat() : 세로로(행) 데이터 합치기
# 새로 만들 데이터프레임명 = pd.merge(왼쪽 데이터, 오른쪽데이터, how ='left', on='결합할 기준') ## how = 'left' : 오른쪽에 입력한 데이터 프레임을 왼쪽 데이터 프레임에 결합한다 라는 뜻 # 중간고사 데이터 만들기 >>> test1 = pd.DataFrame({'id' : [1,2,3,4,5], 'midterm' : [60, 70, 80, 90, 100]}) # 기말고사 데이터 만들기 >>> test2 = pd.DataFrame({'id' : [1,2,3,4,5], 'final' : [70, 60, 83, 95, 99]}) # id를 기준으로 total이라는 데이터 프레임으로 합치기 >>> total = pd.merge(test1, test2, how= 'left', on = 'id') >>> total
#새로 만들 데이터프레임명 = pd.concat([결합할 데이터프레임명1, 결합할 데이터프레임명1]) # 학생 1~5번 시험 데이터 만들기 >>> group_a = pd.DataFrame({'id' : [1,2,3,4,5], 'test' : [60, 70, 80, 90, 100]}) # 학생 6~10번 시험 데이터 만들기 >>> group_b = pd.DataFrame({'id' : [6,7,8,9,10], 'test' : [70, 60, 83, 95, 99]}) # group_all이라는 새로운 데이터 프레임으로 합치기 >>> group_all = pd.concat([group_a, group_b])
🔹 참고) 치트 시트 : 패키지 사용법 요약 매뉴얼
❓ 분석해보기!
#Q1. mpg데이터의 fl변수는 자동차에 사용하는 연료(fuel)를 의미합니다. 다음은 자동차 연료별 가격을 나타낸 표입니다. 우선 이 정보를 이용해 연료와 가격으로 구성된 데이터 프레임을 만들어 보세요. >>> fuel = pd.DataFrame({'fl' : ['c','d','e','p','r'], 'price_fl' : [2.35, 2.38, 2.11, 2.76, 2.22]}) >>> fuel
#Q2. mpg데이터에는 연료종류를 나타낸 fl변수는 있지만 연료 가격을 나타낸 변수는 없습니다. 앞에서 만든 fule데이터를 이용해 mpg데이터에 price_fl(연료 가격) 변수를 추가하세요. >>> mpg = pd.merge(mpg, fuel, how = 'left', on = 'fl') >>> mpg #Q3. 연료 가격 변수가 잘 추가됐는지 확인하기 위해 model, fl, price_fl 변수를 추출해 앞부분 5행을 출력해보세요. >>> mpg[['model', 'fl', 'price_fl']].head()
❓ 또 분석해보기!!
#미국 동북중부 437개 지역의 인구통계 정보를 담고 있는 midwest.csv를 사용해 데이터 분석 문제를 해결해보세요. >>> midwest = pd.read_csv('midwest.csv') >>> midwest #Q1. popadults는 해당 지역의 성인 인구, poptotal은 전체 인구를 나타냅니다. midwest 데이터에 '전체 인구 대비 미성년 인구 백분율' 변수를 추가하세요. >>> midwest = midwest.assign(child_ratio = (1 - midwest['popadults'] / midwest['poptotal']) * 100) >>> midwest #Q2. 미성년 인구 백분율이 가장 높은 상위 5개 county(지역)의 미성년 인구 백분율을 출력하세요. >>> midwest[['county','child_ratio']] \ .sort_values('child_ratio', ascending = False) \ .head() #Q3. 분류표의 기준에 따라 미성년 비율 등급 변수를 추가하고, 각 등급에 몇 개의 지역이 있는지 알아보세요. ## 분류표 : large (40%이상), middle (30~40%이상), small (30%이상) >>> midwest = midwest.assign(child_ratio_category = \ np.where(midwest['child_ratio'] >= 40, 'large', \ np.where(midwest['child_ratio'] >= 30, 'middle','small') ) ) >>> midwest >>> midwest.groupby('child_ratio_category') \ .agg(n = ('child_ratio_category', 'count')) #Q4. popasian은 해당 지역의 아시아인 인구를 나타냅니다. '전체 인구 대비 아시아인 인구 백분율' 변수를 추가하고 하위 10개 지역의 state(주), county(지역), 아시아인 인구 백분율을 출력하세요. >>> midwest = midwest.assign(popasian_ratio = midwest['popasian'] / midwest['poptotal'] * 100) >>> midwest[['state', 'county', 'popasian_ratio']] \ .sort_values(['popasian_ratio']) \ .head(10)
🔷 데이터 정제하기
🔷 결측치 정제하기
🔹 결측치(missing value) ? : 누락된 값, 비어있는 값. 실제 데이터 분석 시 결측치를 확인하고 제거한 후에 분석을 시작해야 함.
#1 결측치를 찾기 전에, 우선 결측치가 있는 데이터프레임 만들기 >>> import pandas as pd >>> import numpy as np >>> df = pd.DataFrame({'sex' : ['M', 'F', np.nan, 'M', 'F'], 'score' : [5,4,3,4,np.nan]}) >>> df ## 결측치는 NumPy패키지의 np.nan으로 입력 ## 표시는 NaN으로 나옴. #2 결측치(NaN)이 있는 상태로 연산하면 출력 결과도 NaN으로 뜸. >>> df['score'] + 1
🔹 결측치 제거하기
★#3 결측치 확인하기 >>> pd.isna(df) #4 결측치 빈도 확인 >>> pd.isna(df).sum() #5 결측치 있는 행 제거하기 >>> df.dropna(subset = ['score']) #6 여러 변수에 결측치 없는 데이터 추출하고 df_nomiss로 저장해주기 (저장을 안하고 df그냥 조회해보면 원본 그대로 나옴) >>> df_nomiss = df.dropna(subset = ['score', 'sex']) >>> df_nomiss #7 결측치가 하나라도 있으면 제거하기 >>> df_nomiss2 = df.dropna() ## 간편하긴하나 분석에 사용할 수 있는 변수까지 제거될 가능성이 있음. ## 예를들어, 성별, 소득, 지역의 데이터를 가지고 성별에 따른 소득 차이를 분석할 때, df.dropna()를 사용 시 지역에 NaN이 있는 행도 제거되어버림.
#8 결측치 제거하지 않고 분석하기 ## pd.mean(), pd.sum(), groupby(), agg()는 결측치가 있으면 결측치를 자동으로 제거하고 연산함 >>> df['score'].mean() 4.0 >>> df['score'].sum() 16.0 >>> df.groupby('sex').agg(mean_score = ('score', 'mean'), sum_score = ('score', 'sum')) mean_score sum_score sex F 4.0 4.0 M 4.5 9.0 ## 자동으로 결측치가 제거되는 기능은 편리하나, 결측치가 있는지 모른채 데이터를 다루게 되는 위험이 있음. ## 직접 결측치를 확인한 후 df.dropna()로 명시적으로 제거 권장
🔹 결측치 대체하기
🔹 결측치 대체하기 : 결측치가 적고 데이터가 크면 결측치를 제거하고 분석할 수 있는데, 데이터가 작고 결측치가 많으면 데이터 손실로 인해 분석 결과의 왜곡이 발생할 수 있음. 이럴 때 결측치를 대체해주면 됨.
🔹 결측치 대체법(imputation) : 결측치를 제거하는 대신 다른 값을 채워 넣는 방법. 평균값이나 최빈값 등 대표값을 구해 일괄 대체를 하거나, 통계 분석 기법으로 결측치의 예측값을 추정 후 대체
#1 위치를 직접 지정해서 원하는 값으로 바꾸기 (지금은 exam에 결측치값이 없으니 결측치를 임의로 넣어서 만들어줌) >>> exam.loc[[2,7,14], ['math']] = np.nan >>> exam ##데이터프레임명.loc[[행번호,행번호,행번호], ['칼럼명']] = 원하는 값 #2 위에서 만든 NaN값에 넣어줄 평균 값을 구해보기 >>> exam['math'].mean() 55.2 #3 평균값 55를 NaN에 넣어주기 >>> exam['math'] = exam['math'].fillna(55) >>> exam ★#4 결측치가 잘 대체되었는지 확인하기 >>> exam['math'].isna().sum() 0
❓ 분석해보기!
# mpg데이터 원본에는 결측치가 없어서, 우선 mpg데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠습니다. >>> mpg = pd.read_csv('mpg.csv') >>> mpg.loc[[64, 123, 130, 152, 211], 'hwy'] = np.nan #Q1. drv(구동 방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기 전에 우선 drv변수와 hwy변수에 결측치가 몇 개 있는지 알아보세요. >>> mpg[['drv', 'hwy']].isna().sum() #Q2. df.dropna()를 이용해 hwy변수의 결측치를 제거하고, 어떤 구동 방식의 hwy평균이 높은지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다. >>> mpg.dropna(subset = ['hwy']) \ .groupby('drv') \ .agg(hwy_mean = ('hwy', 'mean'))
🔷 이상치 정제하기
🔷 이상치(anomaly)? : 정상 범위에서 크게 벗어난 값
🔹 이상치 제거하기 : 실제 데이터에 대부분 이상치가 들어가 있음. 제거하지 않으면 분석의 결과가 왜곡되므로 분석 전에 제거 작업 필요. 이상치는 결측치로 변환 후 제거
#1 이상치를 찾기 전에, 우선 이상치가 있는 데이터프레임 만들기 >>> df = pd.DataFrame({'sex' : [1,2,1,3,2,1], 'score' : [5,4,3,4,2,6]}) >>> df ## 'sex'가 3인 경우 이상치로 가정. ## 'score'가 5 이상인 경우 이상치로 가정. #2 값이 적은 경우 빈도표를 만들어 이상치를 확인할 수 있음. #2-1 'sex'의 빈도표 확인 >>> df['sex'].value_counts().sort_index() #2-1 'score'의 빈도표 확인 >>> df['score'].value_counts().sort_index() #3 이상치를 결측치로 바꾸어주기 #3-1 'sex'가 3인 경우, 이상치로 판단하여 NaN부여 >>> df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex']) >>> df #3-2 'score'가 5보다 크면 NaN 부여 >>> df['score'] = np.where(df['score']>5, np.nan, df['score']) >>> df #4 결측치로 바뀐 이상치였던 것들을 제거하기 >>> df.dropna(subset = ['sex', 'score'])
❗️ np.where()은 문자와 NaN을 함께 반환할 수 없음.
🔹 np.where()을 사용할 때 반환 값 중 문자가 있으면, np.nan으로 지정해도 문자로 'nan'을 반환해버림.
#1 예를 들어, 이런 데이터 프레임을 만들었음. >>> df = pd.DataFrame({'x1' : [1,1,2,2]}) >>> df #2 x2라는 컬럼을 만들면서, x1의 값이 1이면 a를, 1이 아니면 NaN을 반환하도록 명령. >>> df['x2'] = np.where(df['x1'] == 1, 'a', np.nan) >>> df ## 근데 지금 반환값에 'a'라는 문자가 들어가 있음. #3 na의 결과를 확인해보니 na가 없다고 뜸. >>> df.isna()
🔹 그럼 문자랑 NaN을 함께 구성하는 방법은?
#1 결측치로 만들 값에 임의로 문자를 부여함. >>> df['x2'] = np.where(df['x1'] == 1, 'a', 'etc') #2 df.replace()를 사용하여 임의로 부여한 문자를 np.nan으로 바꿔줌 >>> df['x2'] = df['x2'].replace('ect', np.nan) #3 na 확인해보기 >>> df.isna()
🔷 극단적인 이상치, 극단치(outlier) 파악하기
🔹 outlier 기준 정하기 : 논리적 판단, 통계적 기준, 상자 그림을 통해 파악
🔷 상자 그림 (box plot)? : 데이터의 분포를 상자 모양으로 표현한 그래프.
# 상자그림 그래프 불러오기 >>> import seaborn as sns >>> sns.boxplot(data = mpg, y = 'hwy')
🔹 상자그림 그래프 해석
| 상자 그림 | 값 | 설명 |
| 상자 아래 세로선 | 아랫수염 | 하위 0~25% 내에 해당하는 값 |
| 상자 밑면 | 1사분위수(Q1) | 하위 25% 위치 값 |
| 상자 내 굵은 선 | 2사분위수(Q2) | 하위 50% 위치 값(중앙값) |
| 상자 윗면 | 3사분위수(Q3) | 하위 75% 위치 값 |
| 상자 위 세로선 | 윗수염 | 하위 75~100% 내에 해당하는 값 |
| 상자 밖 가로선 | 극단치 경계 | Q1, Q3 밖 1.5 IQR 내 최대값 |
| 상자 밖 점 표식 | 극단치 | Q1, Q3 밖 1.5 IQR을 벗어난 값 |
🔹 (1) 극단치 경계 : 이 부분을 넘어가면 극단치라고 생각해서 점으로 표현하겠습니다.
🔹 (2) IQR 이란? : 1사분위수에서 3사분위수까지의 거리. 박스의 높이라고 생각하면됨.
# 상자그림에서 표시된 부분의 값 자세히 구하기 #1 1사분위수 구하기 >>> pct25 = mpg['hwy'].quantile(.25) >>> pct25 18.0 #2 3사분위수 구하기 >>> pct75 = mpg['hwy'].quantile(.75) >>> pct75 27.0 #3 IQR 구하기 >>> IQR = pct75 - pct25 >>> IQR 9.0 #4 하한 구하기 >>> pct25 - 1.5 * IQR 4.5 #5 상한 구하기 >>> pct75 + 1.5 * IQR 40.5
# 극단치 제거하기 #1 극단치를 결측치로 처리하기 #1-1 하한(4.5)와 상한(40.5)를 벗어나면 NaN부여하기 >>> mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | mpg['hwy'] > 40.5, np.nan, mpg['hwy']) #2 결측치 빈도 확인하기 >>> mpg['hwy'].isna().sum() #3 결측치 제거하기 >>> mpg.dropna(subset = ['hwy']) #4 결측치 제거하고 분석하기 >>> mpg.dropna(subset = ['hwy']) \ .groupby('drv') \ .agg(mean_hwy = ('hwy', 'mean'))
❓ 분석해보기!
# mpg데이터 원본에는 결측치가 없어서, 우선 mpg데이터를 불러와 일부러 몇 개의 값을 결측치로 만들겠습니다. ## drv(구동 방식) 변수의 값은 4, f, r 세 종류인데, 몇 개의 행에 존재할 수 없는 값 k 할당. ## cty(도시 연비) 변수도 몇 개의 행에 극단적으로 크거나 작은 값 할당. >>> mpg = pd.read_csv('mpg.csv') >>> mpg.loc[[9,13,57,92], 'drv'] = 'k' >>> mpg.loc[[28,42,128,202], 'cty'] = [3,4,39,42] #Q1-1. drv에 이상치가 있는지 확인하세요. >>> mpg['drv'].value_counts().sort_index() #Q1-2. 이상치를 결측처리하고 (결측 처리를 할 때는 df.isin()을 활용하세요.) >>> mpg['drv'] = np.where(mpg['drv'].isin(['4', 'f', 'r']), mpg['drv'], np.nan) #Q1-3. 다음 이상치가 사라졌는지 확인하세요. >>> mpg['drv'].value_counts().sort_index() #Q2-1. 상자 그림을 이용해 cty에 이상치가 있는지 확인하세요. >>> sns.boxplot(data = mpg, y = 'cty') #Q2-2. 상자 그림 기준으로 정상 범위를 벗어난 값을 >>> pct25 = mpg['cty'].quantile(.25) >>> pct75 = mpg['cty'].quantile(.75) >>> IQR = pct75 - pct25 #Q2-3. 정상 범위를 벗어난 값 : 하한 구하기 >>> pct25 - 1.5 * IQR 6.5 #Q2-4. 정상 범위를 벗어난 값 : 상한 구하기 >>> pct75 + 1.5 * IQR 26.5 #Q2-5. 결측 처리한 다음 (6.5 이하나, 265. 이상은 NaN부여) >>> mpg['cty'] = np.where(((mpg['cty'] < 6.5) | (mpg['cty'] > 26.5)), np.nan, mpg['cty']) #Q2-6. 다시 상자 그림을 만들어 이상치가 사라졌는지 확인하세요. >>> sns.boxplot(data = mpg, y = 'cty') #Q3. 두 변수의 이상치를 결측 처리했으니 이제 분석할 차례입니다. 이상치를 제거한 다음, drv별로 cty 평균이 어떻게 다른지 알아보세요. 하나의 pandas 구문으로 만드세요. >>> mpg.dropna(subset = ['drv', 'cty']) \ .groupby('drv') \ .agg(mean_cty = ('cty', 'mean'))
'[DA] 데이터 분석' 카테고리의 다른 글
| [성동1기 전Z전능 데이터 분석가] DAY36 - PYTHON PROJECT 1일차 (0) | 2023.12.04 |
|---|---|
| [성동1기 전Z전능 데이터 분석가] DAY35 - 파이썬 기초 (1) | 2023.12.01 |
| [성동1기 전Z전능 데이터 분석가] DAY33 (1) | 2023.11.29 |
| [성동1기 전Z전능 데이터 분석가] DAY32 - 파이썬 기초 (1) | 2023.11.28 |
| [성동1기 전Z전능 데이터 분석가] DAY31 - 파이썬 기초 (1) | 2023.11.27 |